
From OPAC to Conversational Catalog
The arc is familiar. Online public access catalogs replaced card drawers in the 1980s. Faceted discovery layers — Primo, VuFind, EBSCO Discovery Service — replaced bare OPACs in the 2000s, flattening collections into a single search box and a stack of filters. Each transition traded structural fidelity for surface convenience: subject hierarchies collapsed into tag clouds, authority records hid behind autocomplete, and the catalog increasingly behaved like a web search engine that happened to know about books.
The conversational catalog is the next step on that curve. A reader types a question in natural language; a model ingests catalog records, indexed full text, and licensed databases; a synthesized answer comes back, often with inline citations. The interaction feels like talking to a reference librarian. The architecture beneath it does not behave like one.
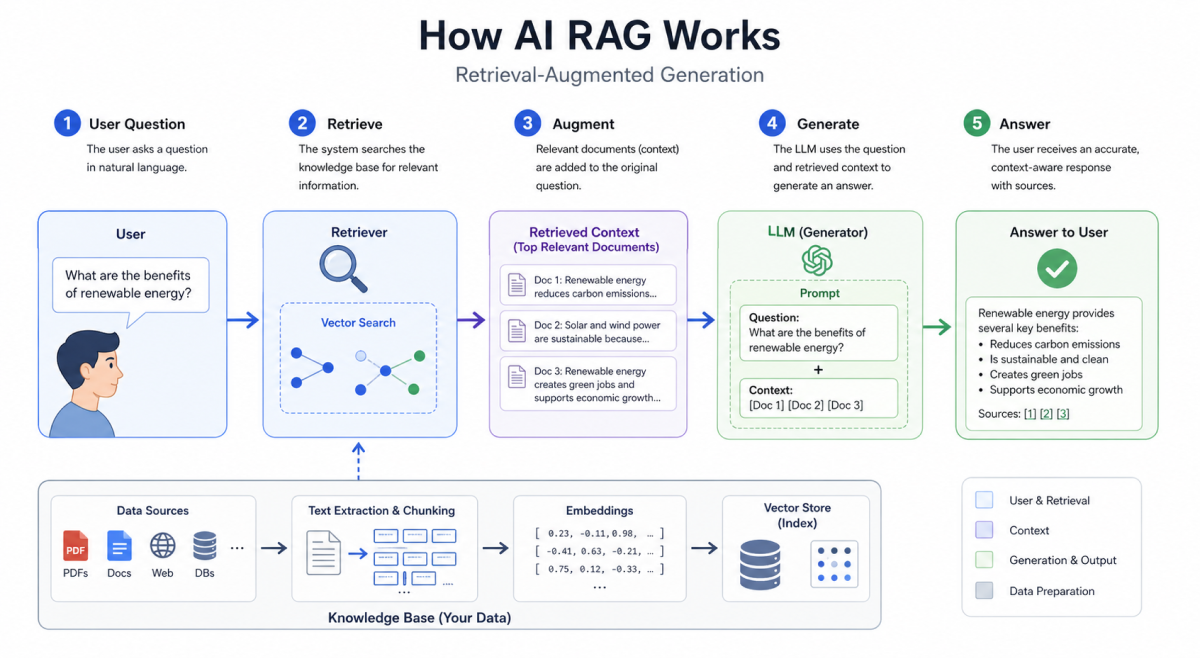
What RAG Actually Retrieves
Retrieval-augmented generation has two halves, and only the first is retrieval. The system embeds catalog records and document chunks into a vector space, finds the chunks closest to the query, and hands them to a language model. The model then writes prose. The citation footnotes the reader sees are produced by the same generative pass that produces the prose — they are predictions about which sources should be cited, not verified pointers to which sources actually grounded the claim.
The failure surface this opens is wider than most procurement teams realize. Embedding drift means that semantically adjacent but factually unrelated chunks can rank identically. Aggressive chunking severs claims from their qualifying context. Re-ranking models trained on web data privilege fluent restatements over canonical sources. The result is an interface that passes a casual smell test, links convincingly to real-looking sources, and confidently asserts findings that the underlying corpus does not contain. In a public library that may produce embarrassment. In a clinical or legal collection it produces harm.
The Cataloger's Inheritance
The discipline already has the answers the vendors are reinventing badly. Library of Congress Subject Headings encode disambiguated meaning. Authority control distinguishes the three different Allison Powells who have published in the last decade. FRBR separates work, expression, manifestation, and item — exactly the four levels at which a generative system silently conflates evidence. The MARC record's 5XX notes carry the kind of provenance metadata a citation engine should be reading in the first place.
None of this infrastructure was designed for retrieval-augmented generation, but all of it solves the problems retrieval-augmented generation now poses. The cataloging tradition's central insight — that a description is only as trustworthy as the chain of decisions behind it — is the missing premise in most current AI-discovery deployments. Vendors are arriving at it through trial and incident reports. Catalogers got there in 1898.
Three Failure Modes in Production
Three patterns have surfaced repeatedly across deployments at HathiTrust partner institutions, Europeana aggregators, and several large academic libraries piloting commercial RAG layers.
The first is the phantom citation: the model produces a plausible reference — author, journal, year, page — that simply does not exist. It is the most visible failure and, paradoxically, the easiest to catch.
The second is the conflated authority: the system treats two distinct entities as one because their embeddings cluster, attaching a paper by one scholar to the biography of another with the same name. It almost never trips an automated check.
The third, and most consequential, is silent collection drift: as licensed content is added or removed from the underlying index without the conversational layer being notified, the system's answers shift accordingly. A query that returned a thoroughly grounded answer in March returns a thinner, partly fabricated version of the same answer in June, and no log records the change. Readers experience the catalog as unstable; they rarely understand why.
A Provenance Contract for RAG Catalogs
A workable response would borrow from cryptographic supply-chain practice and from cataloging both. Four elements form a minimum contract.
First, signed retrievals: every chunk handed to the model carries a tamper-evident identifier tied to the source record and the index version it came from. Second, immutable chunk IDs: a citation in a generated answer resolves to a specific chunk that can be inspected, not a guess at where the claim came from. Third, surfaced confidence: the interface distinguishes claims drawn directly from retrieved sources from claims interpolated by the model — a distinction users currently have no way to make. Fourth, a named source of truth: when the catalog and the language model disagree, the catalog wins, and the disagreement is logged.
None of this requires new science. It requires the field to write down what it already knows.

