A crisis hiding in plain sight
When researchers have systematically tried to reproduce influential published studies, the results have been sobering. Across several large efforts in different fields, a substantial proportion of attempts failed to confirm the original findings. The causes are many: small sample sizes, selective reporting, the relentless incentive to publish novel and positive results rather than careful or negative ones. These are real and much-discussed. But there is a quieter culprit that gets far less attention, and it sits squarely in the domain of information stewardship.
Again and again, when someone tries to reproduce a study, they hit the same wall: the data is gone. Not the paper — the paper is permanent. The data behind it, the raw measurements and the analysis code that turned numbers into conclusions, has vanished. It lived on a departed graduate student's laptop, on a lab server long since wiped, in a file format nothing can open, behind an email address that no longer works. The finding was published; the evidence for it was not preserved. And an experiment whose underlying data cannot be retrieved is, for the purposes of verification, an experiment that cannot be repeated.
Publication is not preservation
For most of its history, science treated the journal article as the unit of knowledge and the data as disposable scaffolding — necessary to build the paper, dispensable once the paper stood. This made a certain sense in an era of print, when storing and sharing raw datasets was genuinely impractical. It makes no sense at all now, and yet the habit persists. The result is a scholarly record that preserves the conclusions while discarding the means of checking them.
This is precisely the distinction digital libraries exist to police. A library has always understood that knowledge is not just the assertion but the apparatus behind it — the citation, the source, the chain of evidence that lets a later reader verify rather than merely believe. Applied to science, that principle is devastatingly simple: if the data is not preserved, described, and retrievable, the claim it supports is an act of faith. Publication tells you what someone found. Only preserved data lets you find out whether they were right.

FAIR is not a slogan
The response taking shape across the research world goes by the acronym FAIR: data that is Findable, Accessible, Interoperable, and Reusable. It sounds like bureaucratic boilerplate, and in careless hands it becomes exactly that. But each word names a real failure point. Data that exists but cannot be found is useless. Data that is found but locked away is useless. Data in a proprietary or undocumented format that no one else can interpret is useless. Data that cannot be combined with other data to ask new questions wastes most of its value.
What FAIR really describes is the application of library science to the laboratory — the unglamorous, essential work of describing a dataset well enough, storing it durably enough, and structuring it openly enough that a stranger years later can use it without phoning the original author. This is not a side task to be handled after the discovery. It is part of what makes the discovery real.
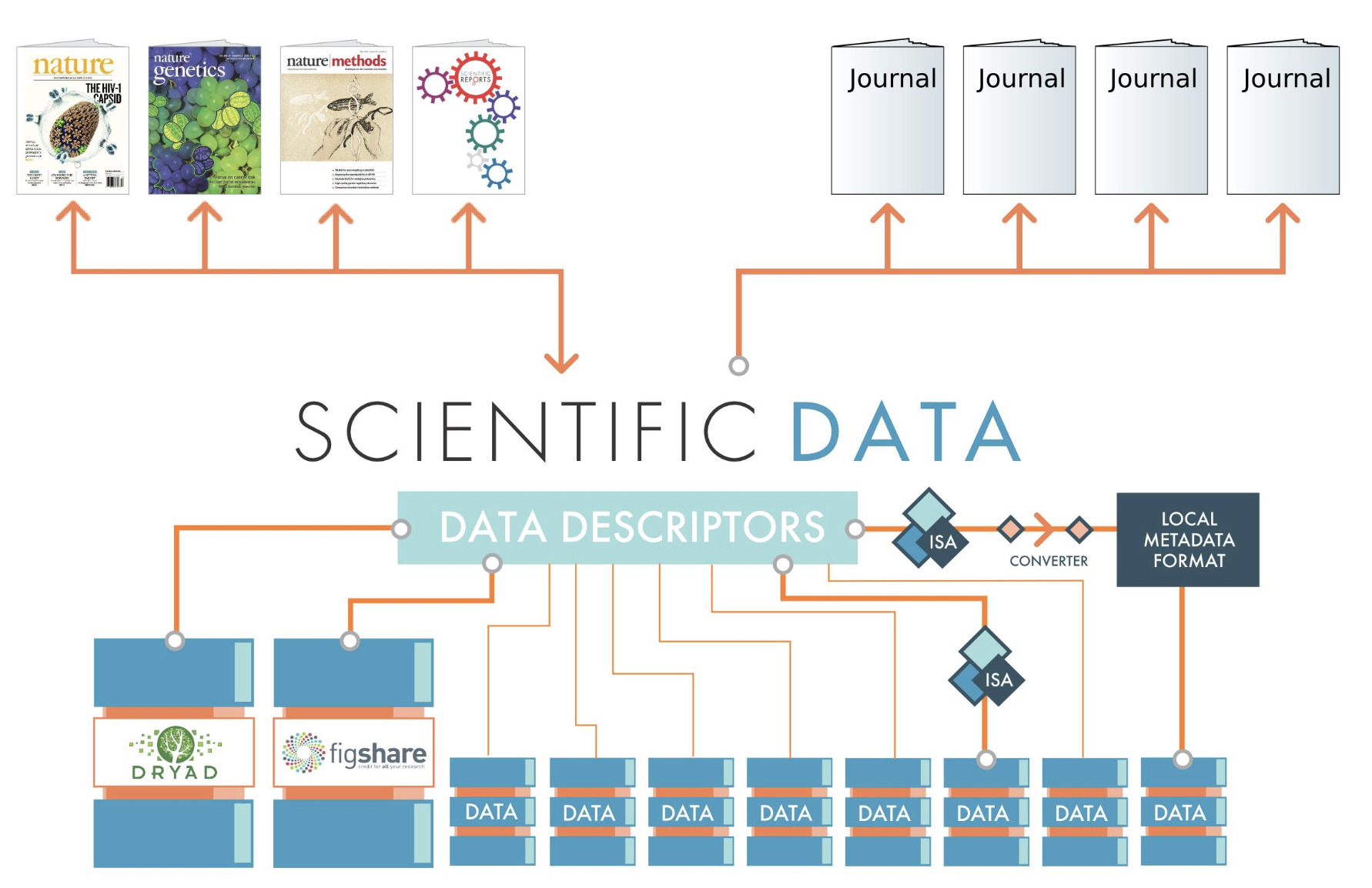
The repository as the new lab notebook
The practical answer is the data repository: trusted, curated archives where the datasets behind published work are deposited, described with rich metadata, and assigned persistent identifiers so they can be cited and found indefinitely. Some fields have built these well — genomics, for instance, established the discipline of depositing sequence data in shared databases early, and it transformed the field. Others lag badly, with data scattered across personal storage and supplementary files that decay the moment the journal's servers change.
The lesson is that reproducibility is not only a matter of better experiments. It is a matter of infrastructure: of treating the dataset as a first-class object of preservation, every bit as worthy of cataloguing and stewardship as the paper it underwrites. The institutions that know how to do this — to describe, preserve, and provide durable access to complex digital objects — are libraries and archives. The reproducibility crisis is, in part, an invitation for them to step into the centre of science.
What the next century owes the record
There is a temptation to treat all this as a technical housekeeping problem, beneath the dignity of the discoveries themselves. That gets it exactly backwards. A finding whose evidence has been lost is not settled knowledge; it is a rumour with a citation. If biomedicine wants its conclusions to mean what it claims they mean, it has to keep the data that earns them, with the same seriousness it brings to the experiments.
The reproducibility crisis, read this way, is less an indictment of scientists than a wake-up call about stewardship. The shelves of the future will not be full of papers alone. They will have to hold the data, the code, and the context that let a finding be checked — or the next generation will inherit a library of confident assertions it has no way to verify. Keeping the evidence is not the boring part of science. It is the part that makes it science at all.
Discover more in our comprehensive guide, where we explain the process in detail and highlight the most important points to consider.